洛拉
译者:片刻小哥哥
项目地址:https://huggingface.apachecn.org/docs/peft/conceptual_guides/lora
原始地址:https://huggingface.co/docs/peft/conceptual_guides/lora
本概念指南简要概述了 LoRA ,一种加速技术 在消耗更少内存的同时对大型模型进行微调。
为了让微调更加高效,LoRA 的做法是用两个较小的来表示权重更新 矩阵(称为 更新矩阵 )通过低阶分解。这些新矩阵可以经过训练以适应 新数据,同时保持较低的更改总数。原始权重矩阵保持冻结状态,不接收 任何进一步的调整。为了产生最终结果,将原始权重和调整后的权重相结合。
这种方法有很多优点:
- LoRA 通过大幅减少可训练参数的数量,使微调更加高效。
- 原始预训练权重保持冻结,这意味着您可以拥有多个轻量级便携式 LoRA 模型,用于在其之上构建的各种下游任务。
- LoRA 与许多其他参数有效的方法正交,并且可以与其中许多方法组合。
- 使用 LoRA 微调的模型的性能与完全微调的模型的性能相当。
- LoRA 不会增加任何推理延迟,因为适配器权重可以与基本模型合并。
原则上,LoRA 可以应用于神经网络中权重矩阵的任何子集,以减少可训练的数量
参数。然而,为了简单性和进一步的参数效率,在 Transformer 模型中 LoRA 通常应用于
仅注意块。 LoRA 模型中可训练参数的数量取决于低秩参数的大小
更新矩阵,主要由rank决定
r
以及原始权重矩阵的形状。
将 LoRA 权重合并到基本模型中
虽然 LoRA 明显更小且训练速度更快,但由于单独加载基础模型和 LoRA 模型,您可能会在推理过程中遇到延迟问题。要消除延迟,请使用 merge_and_unload() 函数将适配器权重与基本模型合并,这使您可以有效地将新合并的模型用作独立模型。
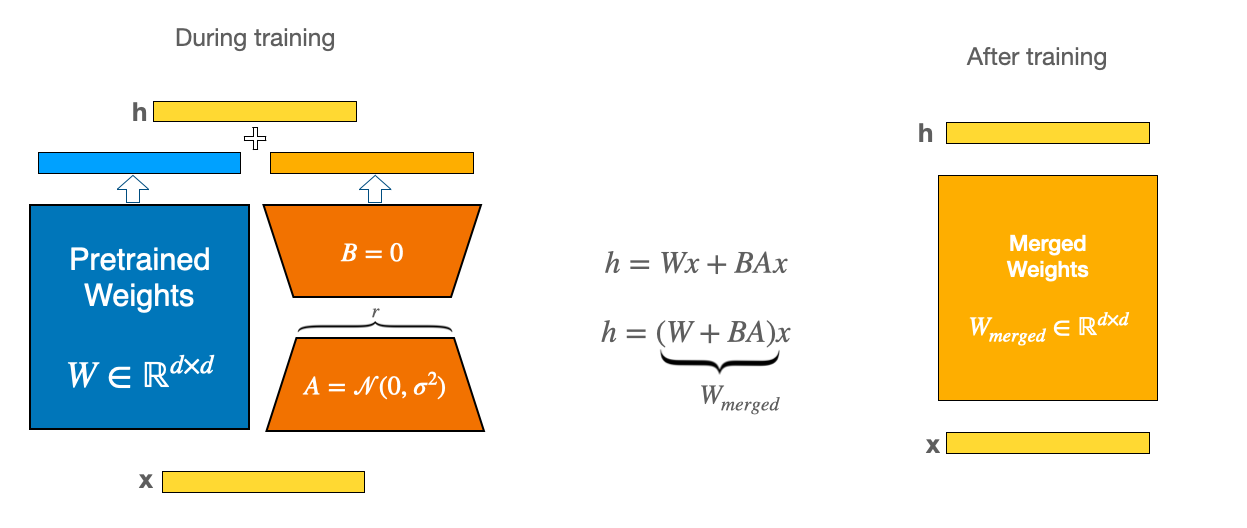
这是有效的,因为在训练期间,较小的权重矩阵( A 和 B 在上图中)是分开的。但是,一旦训练完成,权重实际上可以合并到一个相同的新权重矩阵中。
LoRA 的实用程序
使用
merge_adapter()
将 LoRa 层合并到基础模型中,同时保留 PeftModel。
这将有助于以后取消合并、删除、加载不同的适配器等。
使用
unmerge_adapter()
从基础模型中取消合并 LoRa 层,同时保留 PeftModel。
这将有助于以后合并、删除、加载不同的适配器等。
使用 [卸载()](/docs/peft/v0.6.2/en/package_reference/tuners#peft.LoraModel.unload) 在不合并活动 lora 模块的情况下恢复基本模型。 当您想要在某些应用程序中将模型重置为其原始状态时,这将有所帮助。 例如,在 Stable Diffusion WebUi 中,当用户想要在尝试 LoRA 后使用基础模型进行推断时。
使用 delete_adapter() 删除现有的适配器。
使用 add_weighted_adapter() 根据用户提供的称重方案将多个 LoRA 组合成一个新的适配器。
PEFT中常见的LoRA参数
与 PEFT 支持的其他方法一样,要使用 LoRA 微调模型,您需要:
- 实例化基础模型。
- 创建配置(
LoraConfig) 您可以在其中定义 LoRA 特定参数。 - 将基础模型包裹起来
get_peft_model()获得可训练的佩夫特模型。 - 训练
佩夫特模型就像您通常训练基本模型一样。
LoraConfig
允许您通过以下参数控制 LoRA 如何应用于基础模型:
r:更新矩阵的秩,表示为int。较低的秩会导致较小的更新矩阵和较少的可训练参数。目标模块:应用 LoRA 更新矩阵的模块(例如,注意力块)。阿尔法:LoRA 比例因子。 *偏见:指定是否偏见应该训练参数。可`没有','全部'或者'lora_only'。要保存的模块:除了 LoRA 层之外的模块列表,要设置为可训练并保存在最终检查点中。这些通常包括模型的自定义头,该头是为微调任务随机初始化的。layers_to_transform:LoRA 转换的层列表。如果未指定,则所有层目标模块被改造了。图层模式:匹配图层名称的模式目标模块, 如果要变换的图层已指定。默认情况下佩夫特模型将查看公共层模式(层,h,块等),将其用于异国情调和定制模型。排名模式:从图层名称或正则表达式到与由指定的默认排名不同的排名的映射r。alpha_pattern:从图层名称或正则表达式到 alpha 的映射,与指定的默认 alpha 不同lora_alpha。
LoRA 示例
有关LoRA方法应用于各种下游任务的示例,请参考以下指南:
虽然原始论文重点关注语言模型,但该技术可以应用于深度学习中的任何密集层 楷模。因此,您可以将此技术与扩散模型结合使用。看 Dreambooth 使用 LoRA 进行微调 任务指南为例。
