提示
译者:片刻小哥哥
项目地址:https://huggingface.apachecn.org/docs/peft/conceptual_guides/prompting
原始地址:https://huggingface.co/docs/peft/conceptual_guides/prompting
训练大型预训练语言模型非常耗时且计算密集。随着它们的规模不断增大,人们对更有效的训练方法越来越感兴趣,例如 提示 。提示通过包含描述任务甚至演示任务示例的文本提示,为特定下游任务启动冻结的预训练模型。通过提示,您可以避免为每个下游任务完全训练单独的模型,而是使用相同的冻结预训练模型。这要容易得多,因为您可以使用相同的模型来执行多个不同的任务,并且训练和存储较小的提示参数集比训练所有模型的参数要高效得多。
提示方式有两类:
- 硬提示是带有离散输入标记的手动文本提示;缺点是需要付出很大的努力才能创建一个好的提示
- 软提示是可学习的张量,与可优化为数据集的输入嵌入相连接;缺点是它们不是人类可读的,因为您没有将这些“虚拟标记”与真实单词的嵌入相匹配
本概念指南简要概述了 🤗 PEFT 中包含的软提示方法:提示调优、前缀调优和 P 调优。
及时调整
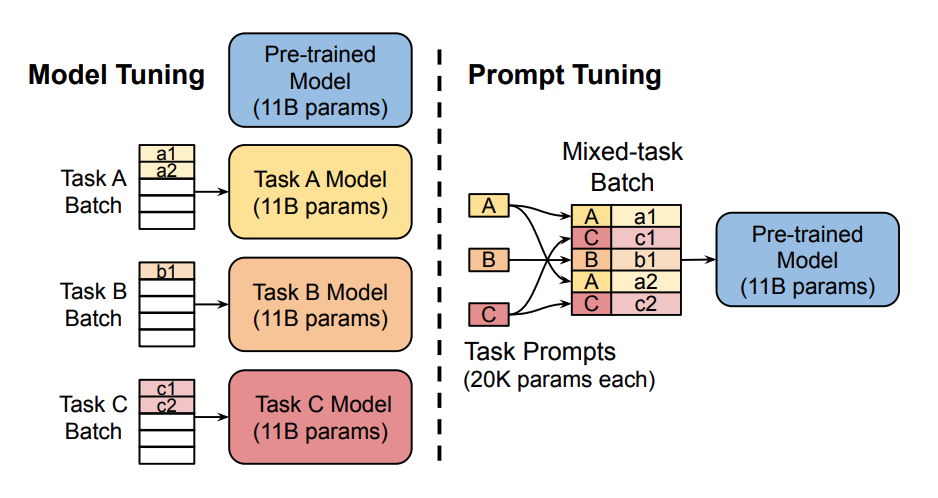
仅训练和存储一组小得多的特定于任务的提示参数 (图片来源) 。
快速调优是针对 T5 模型上的文本分类任务开发的,所有下游任务都被转换为文本生成任务。例如,序列分类通常为文本序列分配单个类别标签。通过将其转换为文本生成任务,构成类标签的标记是 生成 。提示作为一系列标记添加到输入中。通常,模型参数是固定的,这意味着提示标记也由模型参数固定。
提示调整背后的关键思想是提示标记有自己的独立更新的参数。这意味着您可以保持预训练模型的参数冻结,并且仅更新提示标记嵌入的梯度。结果与训练整个模型的传统方法相当,并且随着模型大小的增加而提示调整性能。
看一眼 因果语言建模的提示调整 有关如何通过快速调整来训练模型的分步指南。
前缀调整
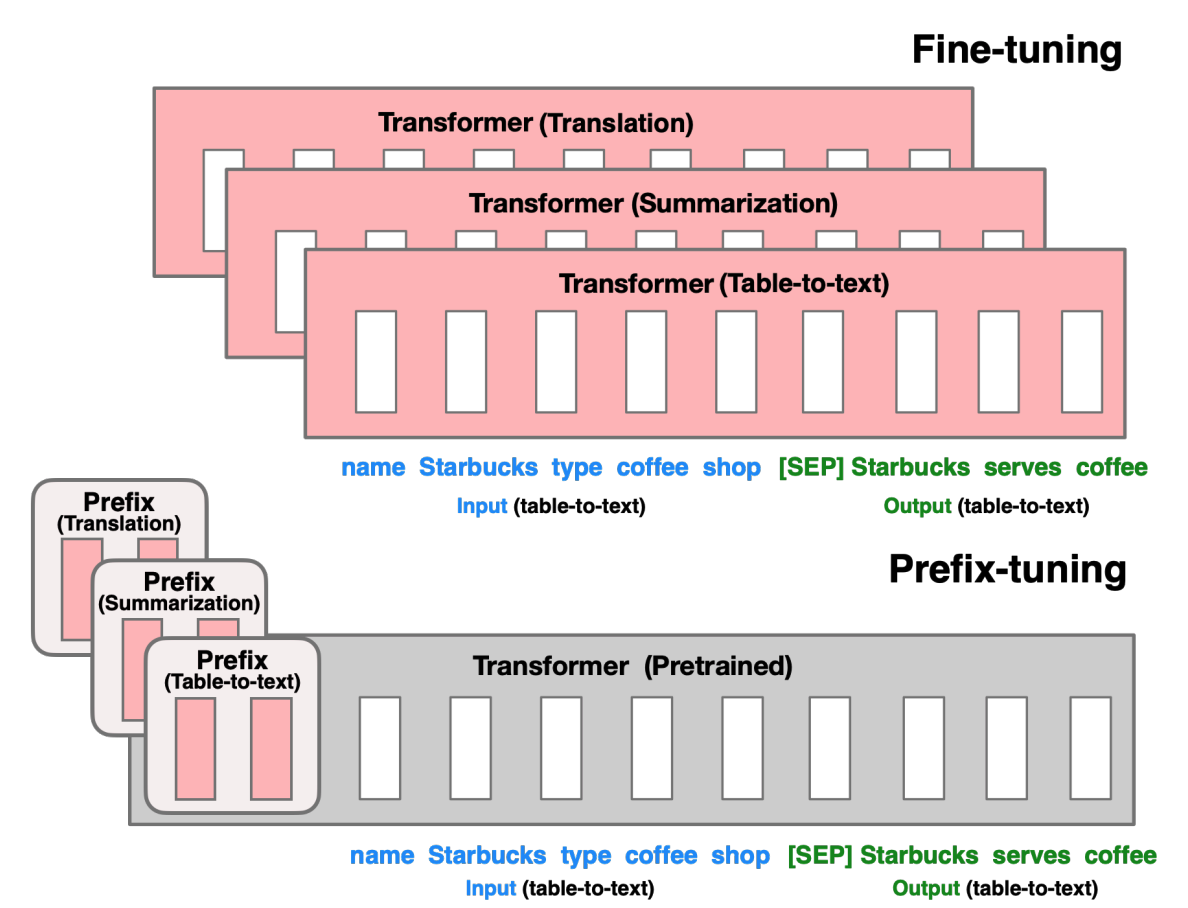
优化每个任务的前缀参数 (图片来源) 。
前缀调优专为 GPT 模型上的自然语言生成 (NLG) 任务而设计。它与提示调音非常相似;前缀调整还将一系列特定于任务的向量添加到输入中,可以对其进行训练和更新,同时保持预训练模型的其余参数冻结。
主要区别在于前缀参数被插入 全部 模型层的,而提示调整仅将提示参数添加到模型输入嵌入中。前缀参数还通过单独的前馈网络(FFN)进行优化,而不是直接在软提示上进行训练,因为这会导致不稳定并损害性能。更新软提示后,FFN 将被丢弃。
结果,作者发现,尽管参数少了 1000 倍,但前缀调优的性能与完全微调模型相当,而且在低数据设置中表现甚至更好。
看一眼 条件生成的前缀调整 有关如何通过前缀调整训练模型的分步指南。
P-调音
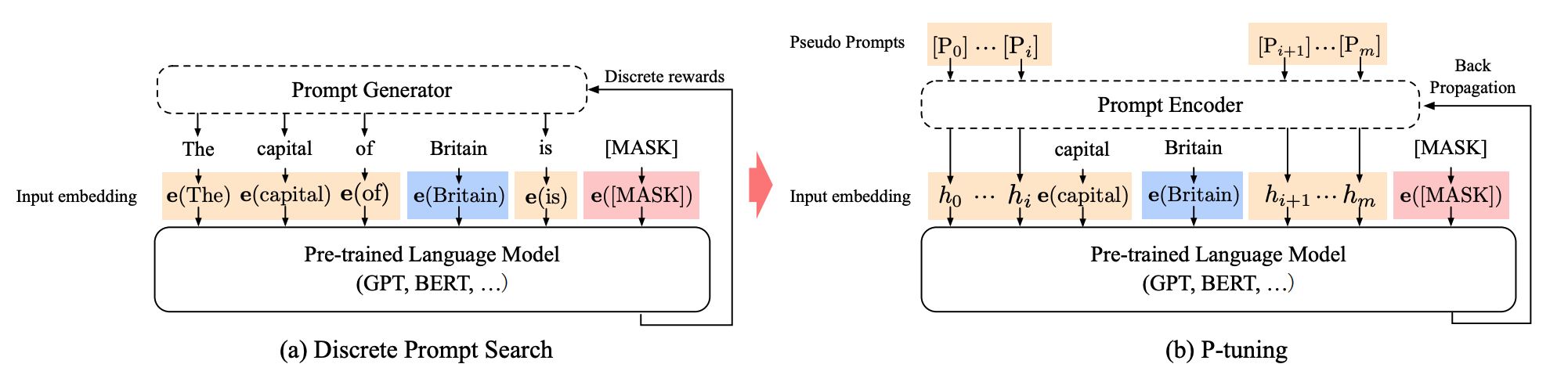
提示标记可以插入输入序列中的任何位置,并且它们由提示编码器优化 (图片来源) 。
P-tuning 专为自然语言理解 (NLU) 任务和所有语言模型而设计。 这是软提示方法的另一种变体; P-tuning 还添加了一个可训练的嵌入张量,可以对其进行优化以找到更好的提示,并且它使用提示编码器(双向长短期记忆网络或 LSTM)来优化提示参数。与前缀调整不同的是:
- 提示标记可以插入到输入序列中的任何位置,并且不仅限于开头
- 提示标记仅添加到输入中,而不是添加到模型的每一层
- 介绍 锚 标记可以提高性能,因为它们指示输入序列中组件的特征
结果表明,P-tuning 比手动制作提示更有效,并且它使类似 GPT 的模型能够在 NLU 任务上与类似 BERT 的模型竞争。
看一眼 序列分类的 P-tuning 有关如何使用 P 调优训练模型的分步指南。
